Uh, so those charts don’t look… particularly impressive at all to anyone else?
Like, don’t get me wrong, it’s definitely an improvement, and it’s looking to be a pretty decent one too. But “stepwise”? When GPT-5 outperformed it at technical non-expert level since ~mid last year, and 5.4 pretty much matches it at Practitioner-level?
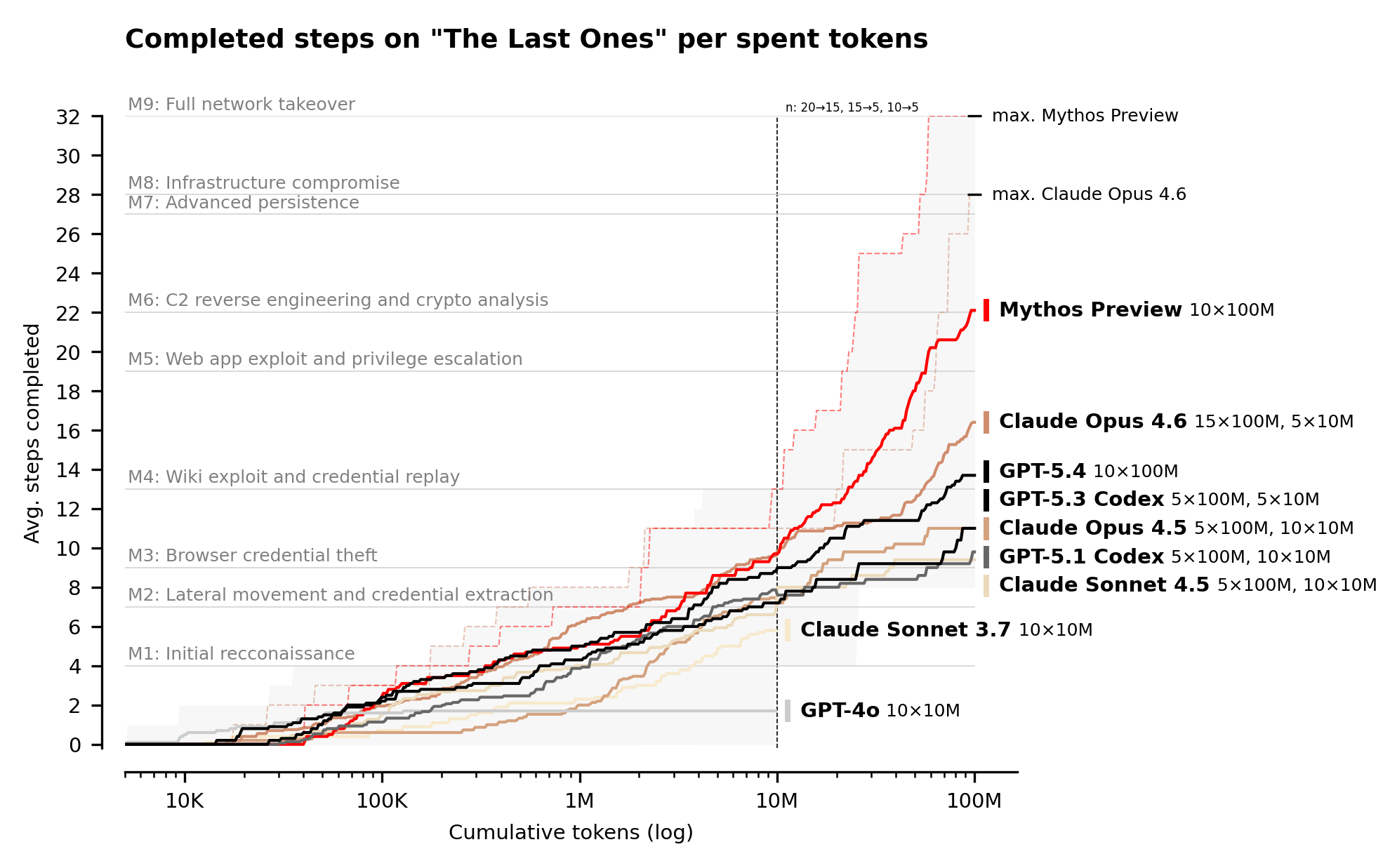
And the charts where Mythos is at the top, it’s usually only by ~7-9 percentage points. It gets an average of 6 more steps than Opus 4.6 in the full takeover simulation. It did manage to complete it as the only model, but… I mean, Opus 4.6 apparently already got pretty close?
And Opus 5 is supposed to be between Mythos and 4.6, which, going by the numbers, would seem to me a smaller jump than between 4.5 and 4.6.
If this is the model they can’t deploy yet because it eats ungodly amounts of compute, then I guess scaling really is a dead end.
I dunno. Maybe I’m reading it wrong. I’d probably be more impressed if Anthropic hadn’t proclaimed The End Times Of Cybersecurity Are Upon Us. And I’d be happy to be proven wrong?
edit:
> We expect that performance on our evaluations would continue to improve with more inference compute: we ran the cyber ranges with a 100M token budget; Mythos Preview’s performance continues to scale up to this limit, and we expect performance improvements would continue beyond that.
Right, so this isn’t the ceiling, it’s just a ceiling at that token allocation. If they were seeing continual improvement up to that limit, then it does stand to reason that bumping the limit further would also bump performance. But then that makes me wonder what effect that would have on the other models. Does the gap grow? Shrink? Stay the same?
Replies
I think the relevant chart to look at is this one:
https://cdn.prod.website-files.com/663bd486c5e4c81588db7a48/...
{kind=link}
Mythos is the first model that can complete all the steps of their "The Last Ones" evaluation, achieving a full network takeover in an automated manner. The Mythos chart does seem to show some takeoff compared with Opus 4.6...
... but only once you get beyond 1 Million tokens. Weirdly, Opus 4.6 seems to match or outperform Mythos in those first Million tokens, at least on this chart. But clearly if you had a budget with tokens to burn - like a nation state - then this is a tool that can automatically get you full network takeover if you can just keep throwing more tokens at it.
The charts are meaningless. They are meant to bring hype until the model gets nerfed after couple of days or weeks where it becomes just like the last model.
The purpose of this model is to try and eat palantirs toast with the unelected bureaucrats in the uk and europe. for the same reason a barrage of anti palantir news has been funded in the past couple months in those countries. the idea of exclusive access is the same product palantir sells to these kind of government boomer (plus steak dinners)
> Uh, so those charts don’t look… particularly impressive at all to anyone else?
I suspect Anthropic gave them early access hoping for a marketing win and ended up with their arse being served to them on a plate.
All rather predictable really. As you say "more compute needed" as the default answer from the AI companies is completely unsustainable.
As for the value of Anthropic blog posts, well...
This article reinforces something I've heard a lot of people say for a while now and what I've personally felt. Claude and GPT are fairly evenly matched on any individual task (GPT might even be a little better), but Claude is far more autonomous.
So with that said, I think the graph under the "Cyber range results" is the important one. The ones at the top show that, yes, Mythos isn't too much better than any of the existing models on well constrained problems, but when the models are given ambiguous challenges that require multiple steps it's much, much better than anything on the market.
I think that's why there's been such a big deal made out of Mythos (well, that and marketing). If Mythos really is so much better than the current models at just working autonomously to find security issues then it becomes much more realistic that someone with deep pockets could just spin up an army of them running 24/7 and point them at a target.