Measuring Claude 4.7's tokenizer costs
Comments
FYI: Anthropic increased people's subscription quotas to counteract the token cost change. In classic Anthropic fashion this is only announced via X post and not any official announcement.
However, if you are using API costs then I guess you're left holding the bag.
I find it interesting that folks are so focused on cost for AI models. Human time spent redirecting AI coding agents towards better strategies and reviewing work, remains dramatically more expensive than the token cost for AI coding, for anything other than hobby work (where you're not paying for the human labor). $200/month is an expensive hobby, but it's negligible as a business expense; SalesForce licenses cost far more.
The key question is how well it a given model does the work, which is a lot harder to measure. But I think token costs are still an order of magnitude below the point where a US-based developer using AI for coding should be asking questions about price; at current price points, the cost/benefit question is dominated by what makes the best use of your limited time as an engineer.
IMHO there is a point where incremental model quality will hit diminishing returns.
It is like comparing an 8K display to a 16K display because at normal viewing distance, the difference is imperceptible, but 16K comes at significant premium.
The same applies to intelligence. Sure, some users might register a meaningful bump, but if 99% can't tell the difference in their day-to-day work, does it matter?
A 20-30% cost increase needs to deliver a proportional leap in perceivable value.
The "multiplier" on Github Copilot went from 3 to 7.5. Nice to see that it is actually only 20-30% and Microsoft wanting to lose money slightly slower.
https://docs.github.com/fr/copilot/reference/ai-models/suppo...
The title is a misdirection. The token counts may be higher, but the cost-per-task may not be for a given intelligence level. Need to wait to see Artificial Analysis' Intelligence Index run for this, or some other independent per-task cost analysis.
The final calculation assumes that Opus 4.7 uses the exact same trajectory + reasoning output as Opus 4.6. I have not verified, but I assume it not to be the case, given that Opus 4.7 on Low thinking is strictly better than Opus 4.6 on Medium, etc., etc.
A question I've been asking alot lately (really since the release of GPT-5.3) is "do I really need the more powerful model"?
I think a big issue with the industry right now is it's constantly chasing higher performing models and that comes at the cost of everything else. What I would love to see in the next few years is all these frontier AI labs go from just trying to create the most powerful model at any cost to actually making the whole thing sustainable and focusing on efficiency.
The GPT-3 era was a taste of what the future could hold but those models were toys compare to what we have today. We saw real gains during the GPT-4 / Claude 3 era where they could start being used as tools but required quite a bit of oversight. Now in the GPT-5 / Claude 4 era I don't really think we need to go much further and start focusing on efficiency and sustainability.
What I would love the industry to start focusing on in the next few years is not on the high end but the low end. Focus on making the 0.5B - 1B parameter models better for specific tasks. I'm currently experimenting with fine-tuning 0.5B models for very specific tasks and long term I think that's the future of AI.
At this point, as an experienced developer, unless they can promise consistent very high quality, which they can't, I would rather lean towards almost as good but faster. At this point, that compromise is Codex.
I would rather steer quickly, get ideas because I'm moving quickly, do course correction quickly - basically I'm not happy blocking my chain of thought/concentration and fall prey to distractions due to Claude's slowness and compaction cycles. Sometimes I don't even notice that Codex has compacted.
For architectural discussions, sure I'll pick Claude. I'm mentally prepared for that. But once we are in the thick of things, speed matters. I would they rather focus on improving Sonnet's speed.
In Kolkata, sweet sellers was struggling with cost management after covid due to increased prices of raw materials. But they couldn't increase the price any further without losing customers. So they reduced the size of sweets instead, and market slowly reduced expectations. And this is the new normal now.
Human psychology is surprisingly similar, and same pattern comes across domains.
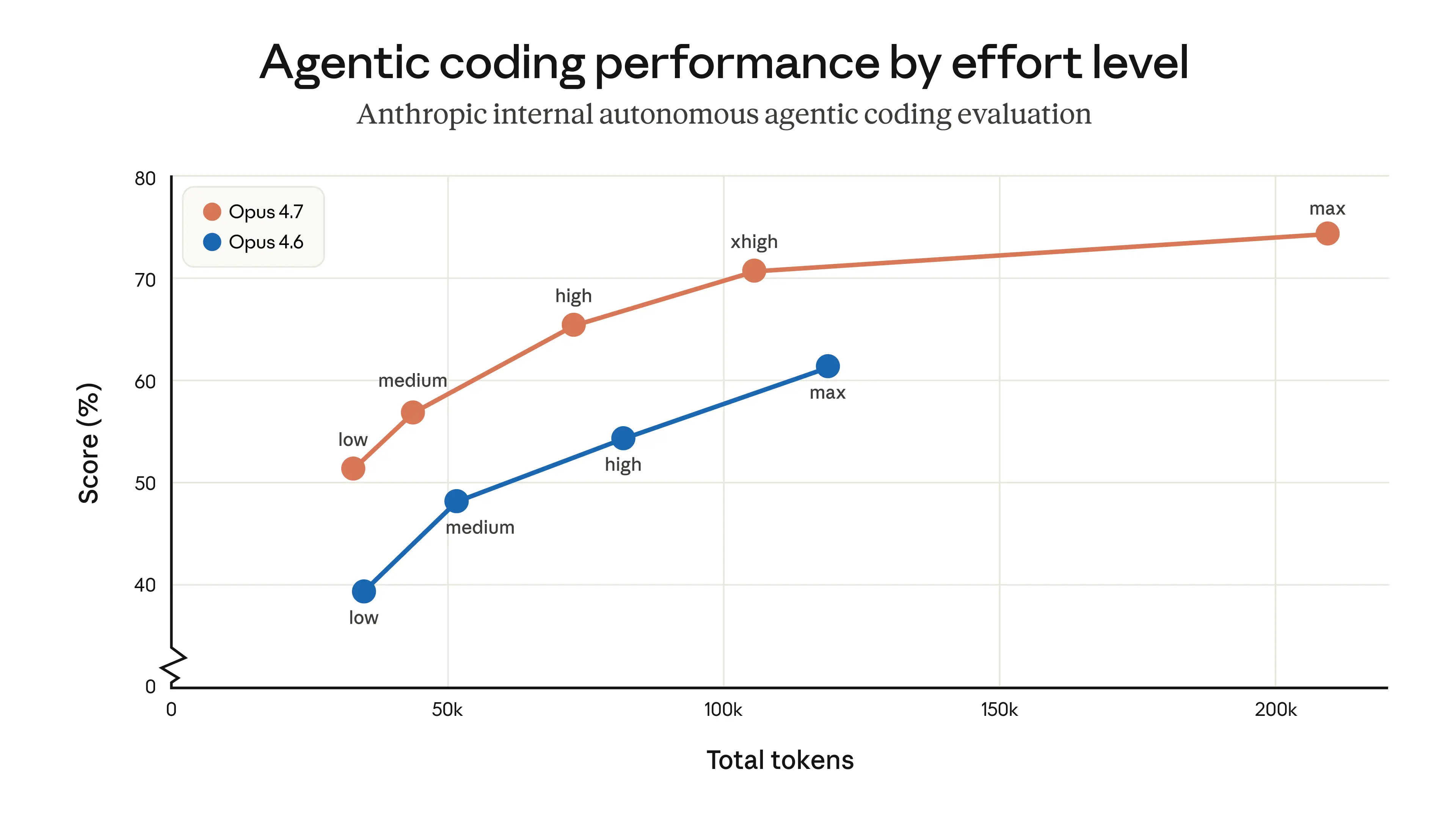
It appears that they are testing using Max. For 4.7 Anthropic recognizes the high token usage of max and recommends the new xhigh mode for most cases. So I think the real question is whether 4.7 xhigh is “better” than 4.6 max.
> max: Max effort can deliver performance gains in some use cases, but may show diminishing returns from increased token usage. This setting can also sometimes be prone to overthinking. We recommend testing max effort for intelligence-demanding tasks.
> xhigh (new): Extra high effort is the best setting for most coding and agentic use cases
Ref: https://platform.claude.com/docs/en/build-with-claude/prompt...
On actual code, I see what you see a 30% increase in tokens which is in-line with what they claim as well. I personally don't tend to feed technical documentation or random pros into llms.
Given that Opus 4.6 and even Sonnet 4.6 are still valid options, for me the question is not "Does 4.7 cost more than claimed?" but "What capabilities does 4.7 give me that 4.6 did not?"
Yesterday 4.6 was a great option and it is too soon for me to tell if 4.7 is a meaningful lift. If it is, then I can evaluate if the increased cost is justified.
I did some work yesterday with Opus and found it amazing.
Today we are almost on non-speaking terms. I'm asking it to do some simple stuff and he's making incredible stupid mistakes:
This is the third time that I have to ask you to remove the issue that was there for more than 20 hours. What is going on here?
| # | Time | Gap before | Session span | API calls |
|---|----------|-----------|--------------|-----------|
| 1 | 15:51:13 | 8s | <1m | 1 |
| 2 | 15:54:35 | 48s | 37m | 51 |
| 3 | 16:33:33 | 2s | 19m | 42 |
| 4 | 16:53:44 | 1s | 9m | 30 |
| 5 | 17:04:37 | 1s | 17m | 30 |
# — sequential compaction event number, ordered by time.
Time — timestamp of the first API call in the resumed session, i.e. when the new context (carrying the compaction summary) was first sent to the
model.
Gap before — time between the last API call of the prior session and the first call of this one. Includes any compaction processing time plus user
think time between the two sessions.
Session span — how long this compaction-resumed session ran, from its first API call to its last before the next compaction (or end of session).
API calls — total number of API requests made during this resumed session. Each tool use, each reply, each intermediate step = one request.
Just yesterday I was happy to have gotten my weekly limit reset [1]. And although I've been doing a lot of mockup work (so a lot of HTML getting written), I think the 1M token stuff is absolutely eating up tokens like CRAZY.
I'm already at 27% of my weekly limit in ONE DAY.
I tried to do my usual test (similar to pelican but a bit more complex) but it ran out of 5 hour limit in 5 minutes. Then after 5 hours I said "go on" and the results were the worst I've ever seen.
Claude code seems to be getting worse on several fronts and better on others. I suspect product is shifting from 'make it great' to 'make it make as much money for us as possible and that includes gathering data'.
Recently it started promoting me for feedback even though I am on API access and have disabled this. When I did a deep dive of their feedback mechanism in the past (months ago so probably changed a lot since then) the feedback prompt was pushing message ids even if you didn't respond. If you are on API usage and have told them no to training on your data then anything pushing a message id implies that it is leaking information about your session. It is hard to keep auditing them when they push so many changes so I am now 'default they are stealing my info' instead of believing their privacy/data use policy claims. Basically, my level of trust is eroding fast in their commitment to not training on me and I am paying a premium to not have that happen.
We noticed this two weeks ago where we found some of our requests are unexpected took more tokens than measured by count_tokens call. At the end they were Anthropic's A/B testing routing some Opus 4.6 calls to Opus 4.7.
https://matrix.dev/blog-2026-04-16.html (We were talking to Opus 4.7 twelve days ago)
Claude seems so frustrating lately to the point where I avoid and completely ignore it. I can't identify a single cause but I believe it's mostly the self-righteousness and leadership that drive all the decisions that make me distrust and disengage with it.
It doesn't look good for Anthropic, especially considering they are burning billions in investor money.
Looks like they lost the mandate of heaven, if Open AI plays it right it might be their end. Add to that the open source models from China.
This is the backdoor way of raising prices... just inflate the token pricing. It's like ice cream companies shrinking the box instead of raising the price
Yeah. I just did a day with 4.7 and I won't be going back for a while. It is just too expensive. On top of the tokenization the thinking seems like it is eating a lot more too.
Interesting because I already felt like current models spit out too much garbage verbose code that a human would write in a far more terse, beautiful and grokable way
Not only that but they seem to have cut my plan ability to use Sonnet too. I have a routine that used to use about 40% of my 5 hour max plan tokens, then since yesterday it gets stopped because it uses the whole 100%. Anyone else experience this?
Some broad assumptions are being made that plans give you a precise equivalent to API cost. This is not the case with reverse engineering plan usage showing cached input is free [0]. If you re-run the math removing cached input the usage cost is ~5-34% more. Was the token plan budget increase [1] proportional to account for this? Can’t say with certainty. Those paying API costs though the price hike is real.
Every time a new model comes out, I'm left guessing what it means for my token budget in order to sustain the quality of output I'm getting. And it varies unpredictably each time. Beyond token efficiency, we need benchmarks to measure model output quality per token consumed for a diverse set of multi-turn conversation scenarios. Measuring single exchanges is not just synthetic, it's unrealistic. Without good cost/quality trade-off measures, every model upgrade feels like a gamble.
Well, LLMs are priced per token, and most of the tokens are just echoing back the old code with minimal changes. So, a lot of the cost is actually paying for the LLM to echo back the same code.
Except, it's not that trivial to solve. I tried experimenting with asking the model to first give a list of symbols it will modify, and then just write the modified symbols. The results were OK, but less refined than when it echoes back the entire file.
The way I see it is that when you echo back the entire file, the process of thinking "should I do an edit here" is distributed over a longer span, so it has more room to make a good decision. Like instead of asking "which 2 of the 10 functions should you change" you're asking it "should you change method1? what about method2? what about method3?", etc., and that puts less pressure on the LLM.
Except, currently we are effectively paying for the LLM to make that decision for *every token*, which is terribly inefficient. So, there has to be some middle ground between expensively echoing back thousands of unchanged tokens and giving an error-ridden high-level summary. We just haven't found that middle ground yet.
"One session" is not a very interesting unit of work. What I am interested in is how much less work I am required to do, to get the results I want.
This is not so much about my instructions being followed more closely. It's the LLM being smarter about what's going on and for example saving me time on unnecessary expeditions. This is where models have been most notably been getting better to my experience. Understanding the bigger picture. Applying taste.
It's harder to measure, of course, but, at least for my coding needs, there is still a lot of room here.
If one session costs an additional 20% that's completely fine, if that session gets me 20% closer to a finished product (or: not 20% further away). Even 10% closer would probably still be entirely fine, given how cheap it is.
News like this always makes me wonder about running my own model, something I've never done. A couple thousand bucks can get you some decent hardware, it looks like, but is it good for coding? What is your all's experience?
And if it's not good enough for coding, what kind of money, if any, would make it good enough?
> Only one instruction type moved materially: change_case:english_capital (0/1 → 1/1). Everything else tied.
So the new tokenizer costs for English/code is to support SHOUTING in English?
Just hit my quota with 20x for the first time today…
That blog post is full of AI slop. Repeats the same argument a gazillion times. It's not X, it's Y. Awful to read.
`/model claude-opus-4-6`
Claude's tokenizers have actually been getting less efficient over the years (I think we're at the third iteration at the least since Sonnet 3.5). And if you prompt the LLM in a language other than English, or if your users prompt it or generate content in other languages, the costs go higher even more. And I mean hundreds of percent more for languages with complex scripts like Tamil or Japanese. If you're interested in the research we did comparing tokenizers of several SOTA models in multiple languages, just hit me up.
Asked Opus 4.7 to extend an existing system today. After thorough exploration and a long back and forth on details it came up with a plan. Then proceeded to build a fully parallel, incompatible system from scratch with the changes I wanted but everything else incompatible and full of placeholders
How can they change the tokenizer without a wholesale pre-train?
Well yeah it was disclosed here https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-... high is the new xhigh
{kind=link}
depends if you're running Opus for everything vs tiering. my pipeline: Haiku 4.5 for ~70% of implementation, Sonnet 4 for one review step, Opus 4.5 only for planning and final synthesis
claude code on opus continuously = whole bill. different measurement.
haiku 4.5 is good enough for fanout. opus earns it on synthesis where you need long context + complex problem solving under constraints
Pretty funny that this article was clearly written by Claude.
To me, all of this seems to be pointing to the future solution being some sort of diffusion-based LLM that can process multiple tokens per pass, while keeping the benefits of more "verbose" token encoding.
Anybody else having problem getting Opus 4.7 to write code? I had it pick up a month-old project, some small one off scripts that I want to modify, and it refused to even touch the code.
So far it costs a lot less, because I'm not going to be using it.
Give it a try to opencode + mimo V2 pro...
I've been using 4.6 models since each of them launched. Same for 4.5.
4.6 performers worse or the same in most of the tasks I have. If there is a parameter that made me use 4.6 more frequently is because 4.5 get dumber and not because 4.6 seemed smarter.
It does cost more but I found the quality of output much higher. I prefer it over the dumbing of effort/models they were doing for the last two months. They have to get users used to picking the appropriate model for their task (or have an automatic mode - but still let me force it to a model).
Yeah I noticed today, I had it work up a spreadsheet for me and I only got 3 or 4 turns in the conversation before it used up all my (pro) credits. It wasn't even super-complicated or anything, only moderately so.
This is probably an adjacent result of this (from anthropic launch post):
> In Claude Code, we’ve raised the default effort level to xhigh for all plans.
Try changing your effort level and see what results you get
Anthropic must be loving it. It's free money.
This is the reality I'm seeing too. Does this mean that the subscriptions (5x, 10x, 20x) are essentially reduced in token-count by 20-30%?
I can manage session cost effectively myself if forking and rewinds were first class features
4.7 one-shot rate is at least 20-30% higher for me
Contrary to people here who feel the price increases, reduction of subscription limits etc are the result of the Anthropic models being more expensive to run than the API & subscription revenue they generate I have a theory that Anthropic has been in the enshittification & rent seeking phase for a while in which they will attempt to extract as much money out of existing users as possible.
Commercial inference providers serve Chinese models of comparable quality at 0.1x-0.25x. I think Anthropic realised that the game is up and they will not be able to hold the lead in quality forever so it's best to switch to value extraction whilst that lead is still somewhat there.
LLMs exist on a logaritmhic performance/cost frontier. It's not really clear whether Opus 4.5+ represent a level shift on this frontier or just inhabits place on that curve which delivers higher performance, but at rapidly diminishing returns to inference cost.
To me, it is hard to reject this hypothesis today. The fact that Anthropic is rapidly trying to increase price may betray the fact that their recent lead is at the cost of dramatically higher operating costs. Their gross margins in this past quarter will be an important data point on this.
I think the tendency for graphs of model assessment to display the log of cost/tokens on the x axis (i.e. Artificial Analysis' site) has obscured this dynamic.